Meeako Is Still Finding Its Brain.

The last few posts were encouraging.
Meeako could answer questions. It remembered context. For the first time it felt like something was actually working. The early wins felt good, but looking back, the bar was low. I was asking simple retrieval questions. Find this, list that, walk me through this flow.
So I stepped it up.
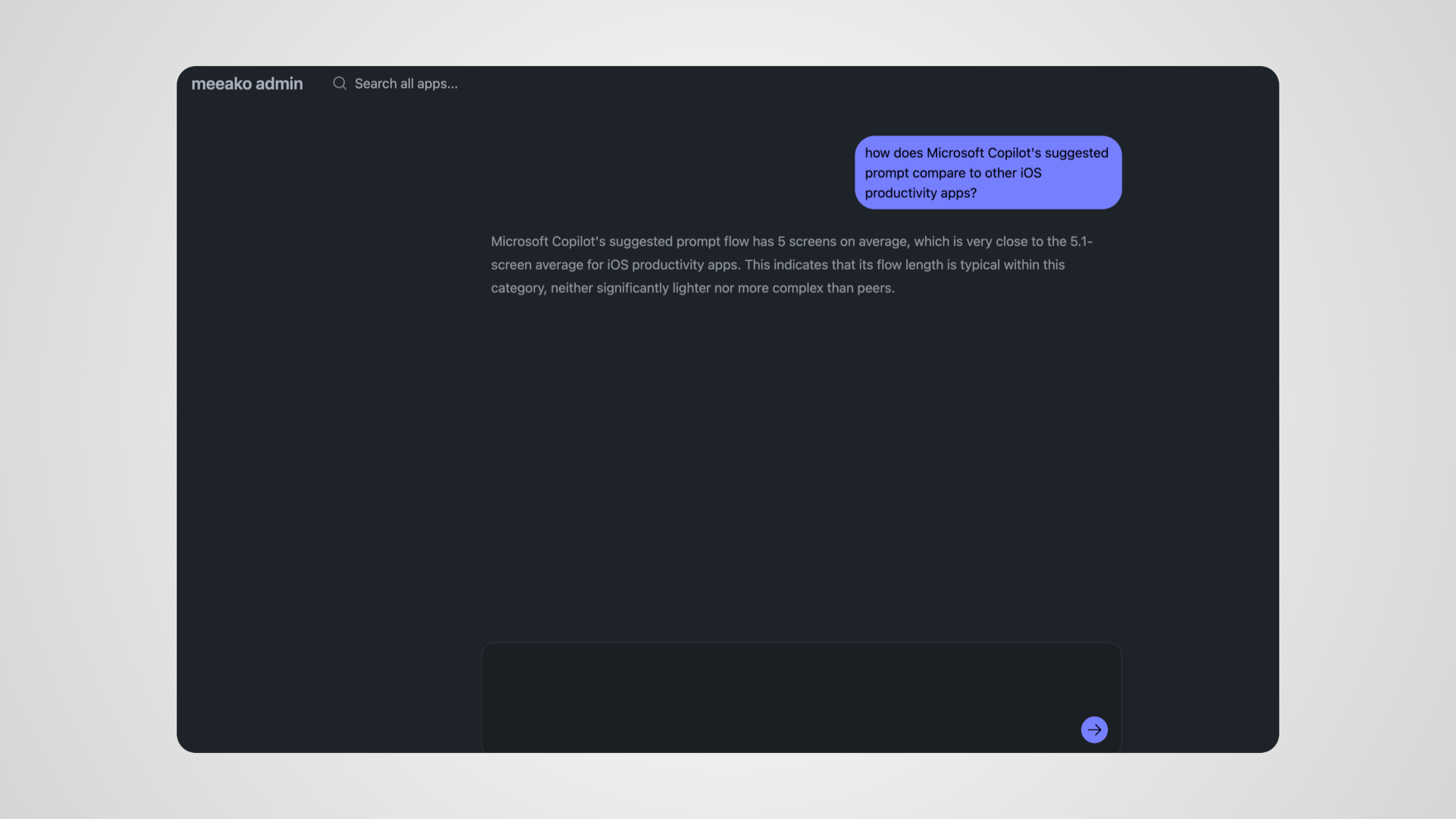
"How does Microsoft Copilot's suggested prompt feature compare to other iOS productivity apps?"
The answer came back:
“Microsoft Copilot's suggested prompt flow has 5 screens on average, which is very close to the 5.1-screen average for iOS productivity apps. This indicates that its flow length is typical within this category, neither significantly lighter nor more complex than peers.”
Meeako AI screenshot of answering How does Microsoft Copilot's suggested prompt feature compare to other iOS productivity apps? question
"5.1-screen average" was made up. The model had hallucinated a number to sound authoritative. And the answer itself told me what, not why.
What I did next
I went looking for a fix. What I found was more complex than I expected.
Building an agentic AI system that actually performs requires finding the right balance across four things:
Context: what information does the AI have access to when answering?
Prompt: how clearly is the task defined?
Tools: what can the AI actually do beyond generating text?
Orchestration: how do you design the flow of decisions and actions across your app?
So I started experimenting one thing at a time.
What I tried
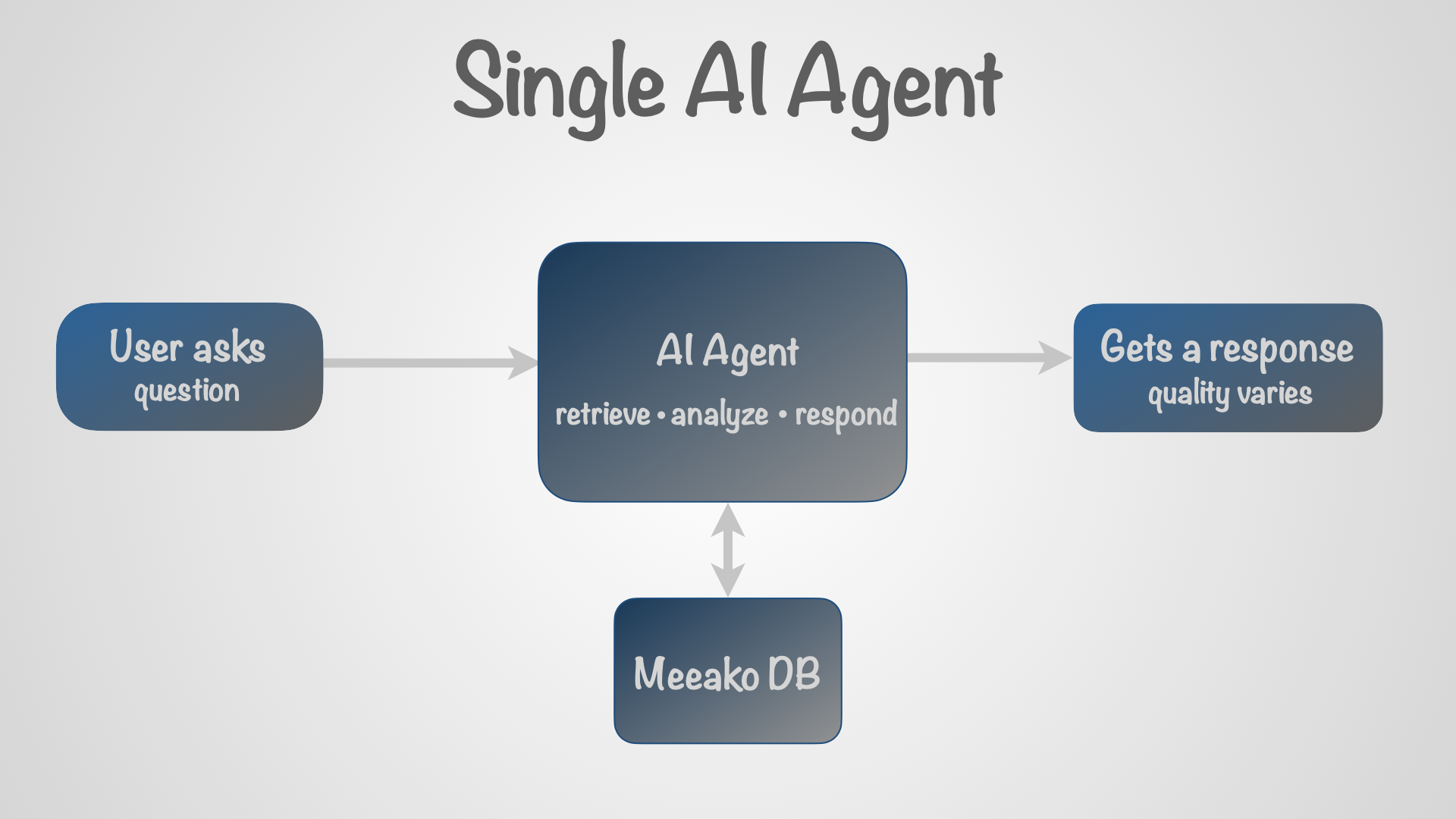
One AI doing everything
My assumption was simple: if ChatGPT can handle any question I throw at it, why wouldn't the same work for Meeako? I gave one AI everything. The database, the question, the memory. And expected it to figure out the rest.
It couldn't. The same brain can't write a casual greeting and do deep strategic analysis well. It over-explains on simple questions. It takes shortcuts on hard ones. And as I saw firsthand, it fills gaps in its knowledge with made up numbers.
Meeako's AI Architecture Experiment: Single AI Agent
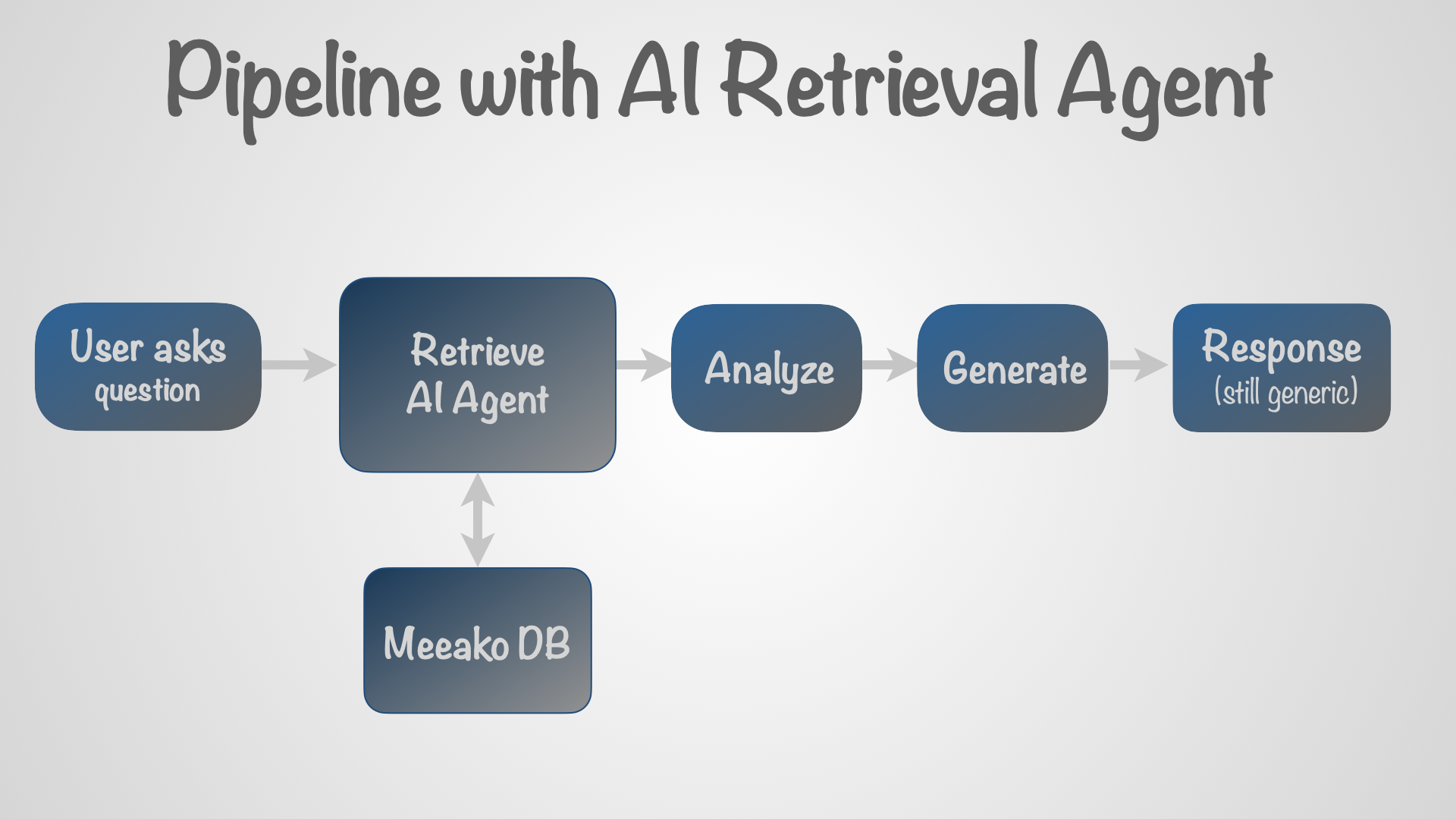
Sequential pipeline with a specialist agent
The problem with one AI seemed obvious in hindsight. Too much happening in one place. So I broke the flow into a pipeline: an AI agent with tools handles retrieval, passes its output to an analyze step, which feeds into generate.
The retrieve step got smarter. But every question ran the full pipeline every time. A simple greeting went through the same steps as a complex strategic question. No routing, no shortcuts. And the generate step still had one system prompt trying to produce every type of answer. Strategic insight came out the same as metric summaries. Not scalable.
Meeako's AI Architecture Experiment: Pipeline with AI Retrieval Agent
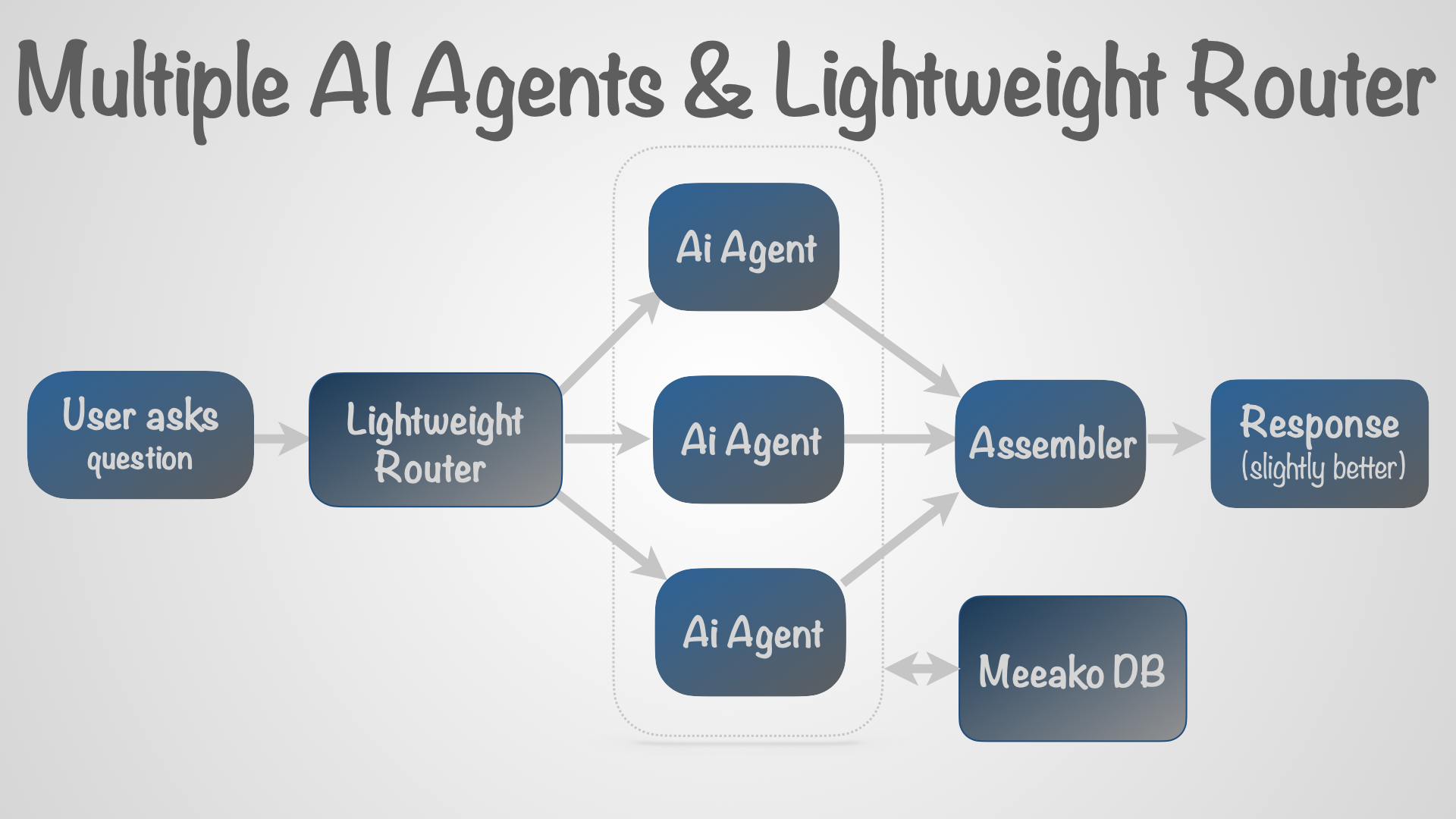
Focused agentic system with a lightweight router (where I am now)
Instead of a sequential pipeline feeding one generator, I gave each question type its own dedicated agent with its own output logic. A smart router decides which agent handles what before the answer is written.
Quality is slightly better. Adding a new question type means adding one agent, not rewriting everything.
But I already know this isn't the final answer either.
Meeako's AI Architecture Experiment: Multiple AI Agents with Lightweight Router
What I'm still figuring out
The open question with approach 3 is orchestration. Specifically, how much of the workflow logic should live in code versus in AI prompts.
Too much in code and it's rigid. It breaks on edge cases. Hard to scale. Too much in AI prompts and it's unpredictable. Hard to debug. Inconsistent.
Finding that balance is the unsolved problem. And I suspect it will define what Meeako can and can't do for a while.
I plan to research this more. Agent orchestration, allowing the LLM to make decisions versus having code make them, is where I'm headed next.